
Systems engineering is the part of project management that deals with defining and developing a system (as opposed to contracts and resource allocation). Systems engineering provides the background and definitions so that the next step of project execution can occur. Often there is a cyclical process of looking at requirement definitions from the systems engineer and the execution lead (or project manager).
System engineers need to look at both the internal components of the system being developed and the outside factors such as thermal, users, environment, etc.. They need to have a good understanding of the various disciplines involved in the system being designed (some people will argue with this, but all of the good system engineers I have worked with had a good understanding of the subsystems involved).
Some of the disciplines that a system engineer might need to know:
- Electrical
- Electronic
- Eletro-mechanical
- Mechanical
- Thermal
- Optical
- Embedded Software
- High level Software
Satisficing is a concept developed by Herb Simon. You can either create an optimal decision for a simplified world, or a satisfactory decision for the real world. System engineers need to determine the best balance between cost, time, “best option”, and other constraints. There are often criteria for what is acceptable, what is desired, and what would be great to have; that needs to be balanced.
When looking at external interactions there are many possible interactions, including:
- Interfaces to other systems (switches, signals, lights, mounting surfaces, connectors, etc..) (ie. Inputs & Outputs)
- Users
- Maintenance & Repairs
- Operations
- Storage & Usage Environment
- Shipping
Often there is no (easy to determine) quantitative method to determine the proper path, and you need to use qualitative assessments and prior experience to guide your decisions. When proper quantitative results are not available, back of the envelope calculations can often be used to sanity check parts of a design.
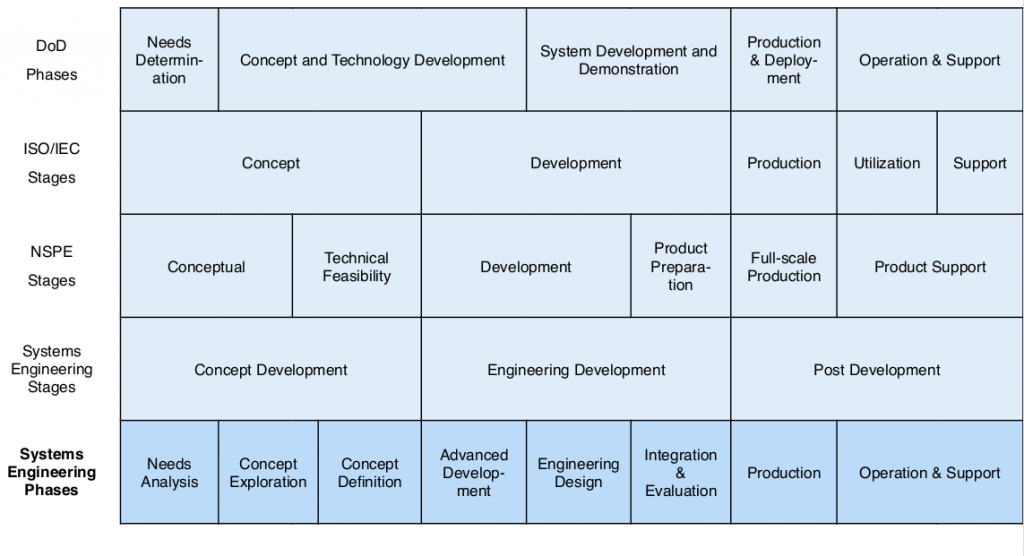
There are many approaches to looking at the life cycle of a project. Military, NASA, researchers, etc.. each have their own approach to the life of their projects and the items produced by those projects. For example this is a common “V” process flow.

And here is a common spiral process flow.

Here is my version (without a fancy graphic):
- Project Definition (stating the correct problem)
- Requirement Definitions
- High Level Design & Validation
- Detailed Design & Testing
- Fabrication
- Acceptance Testing
- Team Dinner
- Production & Deployment
- Support & Maintenance
- Retirement / End-of-Life
- Team Dinner
There are two stages above that are often omitted, but should not be. The team dinner. Project leads (and companies) should help build the team and celebrate milestones/success by treating the team to a dinner & beers. This is an old custom that should not be neglected.
In each of the steps above the risk is further reduced. At the onset there is a high risk to the project’s success. As the system gets defined, sub-components are tested and simulated and then finally built, the overall risk should go down and the confidence in the project should increase.
Along the design path, design reviews are commonly conducted. Design reviews give you a chance to show your work to other external experts to get feedback and more importantly try to find risks and things that can fail. Preliminary Design Reviews (PDR) are often done after having a design and some validation of the design, but before the engineering and detailed designs are produced. The Critical Design Review (CDR) is performed when the design is built and the team has a high confidence in that design. On large projects there can be multiple design reviews between the PDR and CDR. The design reviews should address the problem being solved, the design, schedule, budget risks, and other relevant issues. On small projects there might only be one design review.
Risk needs to be addressed in the requirements. To do this a risk assessment needs to be done. All risks should be assigned a “likelihood of risk” and a “criticality of that risk” value. The value can be as simple as high, medium, and low; or a numeric value over a larger scale. I like keeping it simple since when people use numbers they are often made up and have no real value. This risk assessment and the corresponding risk mitigation strategies will often be presented during the design review. Items with a high likelihood of risk and a high criticality of risk, really need to be addressed and a determination to reduce that risk is critical. I usually order the list by criticality of the risk, followed by the likelihood.
| Risk | Likelihood | Criticality |
|---|---|---|
| Vehicle losing control while driving | medium | high |
| Human jumping in front of vehicle | low | high |
| Timeline | high | medium |
| LIDAR Failing | low | medium |
| Exceeding project budget | medium | low |
| Seat fabric ripping | low | low |
Sample risk assessment table
System Requirements
This section probably should be at the beginning of this post due to the importance of defining requirements early on in a project; (however its not…)
While forming requirements there are often two sets; the absolute requirements for the system (often based on external requirements), and internal requirements for the design (based on what you want). It is also standard practice to phrase the requirements with the word shall. The requirements should mostly have a quantitative way of verifying that the requirement has been met.
A sample requirements document is below
| id | Requirement | Source | Notes | Author | Date Added | Responsible Team |
|---|---|---|---|---|---|---|
| 1 | ROBOT | |||||
| 1.1 | Vehicle shall have a minimum turn radius of 3meters | Internal | To allow control while driving | David | 3/1/16 | Vehicle |
| 1.2 | Vehicle shall come to a complete stop in <3seconds when e-stopped and traveling 60kph | Legal code section 3.2.1 | verify with stopwatch | David | 3/4/16 | Vehicle |
| 1.3 | Vehicle shall come to complete stop in 5 meters after an e-stop while traveling 60kph | Legal code section 3.2.1.2 | verify with laser | David | 3/4/16 | Vehicle |
| 1.4 | Vehicle shall be able to identify an obstacle with a size greater than 10cm tall | Legal code section 3.2.2 | David | 3/4/16 | Perception | |
| 2 | TESTING | |||||
| 2.1 | Testing area shall have safety signs to block area | Legal code section 3.5.1 | Letters 6inch height | Mike | 3/9/16 | Test |
| 2.2 | Chase vehicle shall be used when vehicle unmanned | Legal code section 3.2.6 | Paul | 3/4/16 | Test | |
| 3 | SOFTWARE ARCHITECTURE | |||||
| 3.1 | Operator shall be able to change aggressiveness of vehicle | Internal | from a single location | Mike | 3/9/16 | Software |
| 3.2 | Code running on the robot shall be linked to a specific build version in the repository. | Internal | from git repo | Mike | 3/9/16 | Software |
This document can later be adapted as your test metrics. You can add pass, fail, validation methods, etc… to this form and then keep track of where your system is. For example you can run a regression test every Friday and based on that test you update the pass/fail fields. You can color the rows to make the chart easy for people to follow your progress. This report should be emailed out after your testing (or some other interval).
Here are some sample colors that I use:
- Red – Fail
- Green – Pass
- Yellow – Pass with comments
- Blue – Not tested
- Grey – Not Tested AND not developed yet
Reliability Determination
The reliability of the entire system working is the product of all of the individual components.
SYSTEM_RELIABILITY = SUBSYSTEM_1 * SUBSYSTEM_2 * SUBSYSTEM_n
So if you have 10 subsystems you need each of them to be 99.9% reliable to make the full system reliability be 99%.
If you can not achieve the required reliability you might need to look into redundancy. If you have two items for redundancy that are each 99% reliable you can compute the overall reliability:
TOTAL_RELIABILITY = 1 – [ (1 – INSTANCE_RELIABILITY_1) * (1 – INSTANCE_RELIABILITY_2) ]
or
0.9999 = 1 – [ (1 – 0.99) * (1 – 0.99) ] or 99.99%
I hope you found this interesting. I have some other system engineering type posts coming up. If you have comments or things you want to see, leave it in the comments below.


Pingback: Hands On Ground Robot & Drone Design Series - Robots For Roboticists
Pingback: Mechanical & Wheels - Hands On Ground Robot Design - Robots For Roboticists